
Data Quality
Efficient processes require a high-quality database
Bring your customer data to the highest level
The basis and prerequisite for optimized processes in a company is credible and resilient corporate data. High data quality accelerates your business processes and gives you a competitive advantage that should not be underestimated.

The optimum for your data.
To get the most out of your data, you need to understand, maintain, protect and monitor it. And that in terms of efficient data quality management across the entire data quality lifecycle. We offer you a combination of powerful tools and experienced consultants to help you master these tasks.
Our data quality solutions fit into your IT structure and meet your requirements precisely. This ensures that your data always meets business requirements and minimizes the risk of data management projects of any kind. When optimizing your business partner data, we aim to offer you the highest quality results with the best performance.
We offer you the best quality
- Data quality solutions from a single source.
- Support from experienced consultants and 50+ years of experience.
- Guarantee of the required data quality.
- Runnability on all common platforms.
- Cost optimization through hybrid solutions.
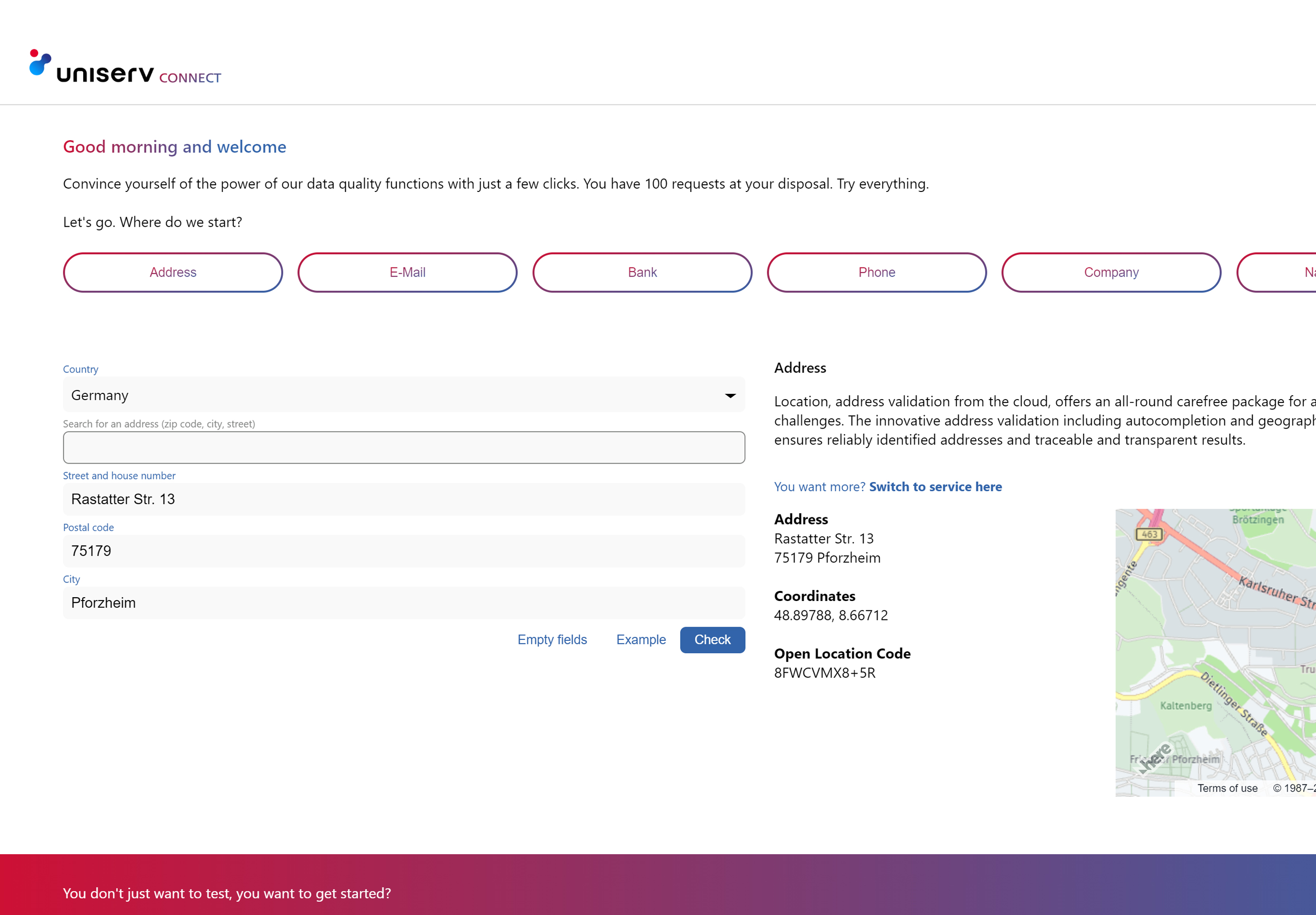
Test our data quality tools
Test and discover our Data Quality Services from the cloud in Uniserv CONNECT free of charge and without obligation. Interactively check address, contact, company and bank data. What to expect:
- 100 free requests. Test all services extensively & free of charge.
- API documentation. All integration & interface details.
- Discover & try out. Clear examples of different use cases.
- Questions? Our experts are ready to help you.

Success with perfect & high-quality customer master data
Data plays a key role in many business areas such as sales, marketing and finance. With our customized data quality solutions, you can turn your customer master data into a success factor for your company:
- We ensure high data quality at every location in your company - even internationally.
- We offer address information correction based on excellent reference data.
- We check e-mail addresses, telephone numbers or bank data at various levels.
- We upgrade your master data - for example by enriching it with geo-coordinates or industry keys.
If you have redundancies in your data, we search for duplicates very flexibly, taking your business rules into account. These can be consolidated automatically as far as possible on the basis of rules or can be controlled out for manual postprocessing.
With the Uniserv software, you have a high-quality database which meets your requirements. This not only increases the efficiency of your employees, but the company processes also run more smoothly and you operate more successfully on the market. And this is ultimately also reflected in your company figures.

The four levels of data quality
We will show you four steps that must be taken into account when it comes to the quality of the data so that it ultimately becomes a real asset for your company. Only the best for your data.
Download the Uniserv Business Whitepaper now.
Top companies trust in data quality software from Uniserv













FAQs
In discussions with our customers and employees from the various departments, we are repeatedly told about similar symptoms of poor data quality. From the symptoms, clues for concrete data quality initiatives can be derived, resulting in initial indications for the creation of the catalog of measures:
- Customers and business partners appear more than once in the system
- Contact persons are not up-to-date
- High return rate for mailing campaigns due to incorrect or incomplete addresses
- Customer complaints about multiple deliveries of the same advertising mailings
- Low response rates for marketing campaigns
- Incorrect letter salutations and address lines, for example, if Mr. Katrin Müller and Mrs. Walter Schmitt receive mail from you
- Cross- and up-selling opportunities cannot be identified
- Low user acceptance and complaints from employees
- Legal requirements cannot be met
- Lack of planning security: Strategic decisions are only made with great uncertainty
Right up front: Incorrect addresses and poor data quality are a cost factor that companies could simply avoid!
In Germany, around 14 million addresses change each year as a result of relocations and around 990,000 as a result of deaths. Many of the total 370,000 marriages and 150,000 divorces each year are associated with name changes. In addition, there are thousands of changes in street names, postal codes and towns each year. Most changes occur at the address - the CRM is not necessarily up-to-date.
Correct postal addresses are of central importance for companies. Only correct addresses ensure the deliverability of mailings, minimize postage and advertising expenses, and are an indispensable prerequisite for identifying duplicates. Read our paper "How much does bad data cost?" to find out when data is bad, what avoidable costs it causes, and how you can avoid these costs in the future.
The aim is to improve data quality and manage it on an ongoing basis. This is not a one-time task, because almost all data in companies, especially customer data, is subject to constant change. The goal must therefore be to ensure that customer information is constantly available in a consistent, complete and up-to-date form. Nevertheless, companies usually improve their data quality only in phases, for example, because a new project provides an occasion to do so (and corresponding budgets are available). Afterwards, however, the quality usually deteriorates again. This is in the nature of things, because data changes due to new circumstances, such as a change in a mobile phone number or an address.
When we talk about data quality management, we are talking about an approach that ensures the quality of data throughout its entire lifecycle - from its capture, storage and use to its archiving and deletion. The closed-loop approach from Total Quality Management is commonly used here. To begin with, customer data is already checked during data capture using DQ services. Incorrect customer data that cannot be automatically corrected is stored in an intermediate database and a report or alert is sent to the entry point so that it can take corrective action.
This cycle allows customer data to be continuously reviewed as it is entered and processed. If regular reports are written about these processes (for example, via a data quality dashboard), users can measure the performance of the closed loop for data quality management (performance management) and continuously improve the process. The result is almost constant data quality at a high level.
However, data quality does not stop there. Companies are predominantly structured in such a way that DQ management generates an excessive amount of work because data sovereignty usually lies with the departments. As a result, different departments or newly developed business units cannot access all customer data in the company. The data pots do not match. In such constellations, data quality management is limited to separate system silos. These silos contain a lot of customer data, the quality of which could be improved and enriched by merging it with available data throughout the company. But de facto, the existing structures and processes cause high costs due to redundancies.
And what is even more serious: Companies are squandering the great potential that lies in their databases - namely, the opportunity for a unified view of their customers. The reality is sobering, because companies lack an overview and their management can hardly rely on the data as a basis for decisions and measures. Wrong decisions and bad investments can be the expensive consequence. The need for data quality is obvious. However, in order for the success of comprehensive data quality management to actually have an impact on the daily work of employees and the business success of the entire company, master data management is necessary.
Regardless of their structure and organization, companies should take a step-by-step approach to reviewing their data quality. First, two areas that are closely intertwined must be assessed: The quality of the data and the processes associated with it. As data is used in business processes, processes describe its intended use and specify the necessary data format. For example, if qualified leads are available in an Excel spreadsheet (format) and are to be used for mailings (process), the format must be adapted accordingly. This includes adding to data fields, enriching them and coding them so that they are importable for the mailing tool. Accordingly, each process has an impact on data quality. In practice, many employees are often not even aware of the intended use of data and thus the further process; the lack of awareness of this alone ensures errors.
1. Recognize symptoms and causes
Clues to any data quality assessment are symptoms that need to be analyzed. For example, if employees complain about a high manual research effort or rework when creating customer lists, these complaints must be recognized as symptoms. The cause may be a lack of up-to-date data or a lack of employee confidence in the data. So while insufficient data quality must now be assumed, it is also necessary to check whether existing processes are influencing this.
Another example is the multiple appearance of customers and business partners in data-carrying systems (duplicates). An analysis of the processes may reveal that employees do not check whether new customers already exist in the system before creating them.
In order to track down symptoms and causes, employees who regularly work with the data should be included in the process if possible. The data objects and processes to be analyzed are derived from the respective symptoms and causes. In addition, those responsible can and should derive from this what corporate master data must look like so that all employees working with it can use it efficiently.
2. Profiling
The next step is to substantiate the employees' "gut feeling" and experiential knowledge about the status of data quality with analysis results. The goal is to show the status quo of the data and to make an informed statement about the completeness, correctness and redundancy of the data. The result of this profiling should answer the following questions:
- What information is missing?
- Where do suspicious outliers appear?
- Where does the format not match the meaning?
- Where are two or more attributes inconsistent?
- Where are predetermined rules violated?
- In what context do errors occur?
- How does an error present itself in different data segments (different regions, different collection periods, etc.)?
- How does the occurrence of errors change over time?
- To answer these questions, it is advisable to use software that automatically searches for gaps, errors and correlations within a dataset, compiles them and thus provides the basis for the analysis result.
Data profiling is a crucial step - if companies skip this point, which is often the case, they take their measures to improve data quality on the off chance. This is because if those responsible do not clearly know their data basis, they initiate measures based on gut feeling, but do not investigate all causes. As a result, their data remains unreliable and employees continue to put up with bumpy processes and poor data quality.
How good do you think your data actually is? When it comes to the quality of your own data, you shouldn't just rely on a vague gut feeling. So how do you make it measurable? The Uniserv Data Assessment provides a remedy: we obtain an exact overview of the current condition of your data and evaluate it according to standardized data quality criteria.
3. Create a catalog of measures
On the basis of the profiling, measures are defined which bring the data and process quality to the highest level. This can be to specify the intended use of data and the requirements for it, or to introduce a real-time address check. If you want to get a grip on duplicates, a real-time duplicate check could be the solution. The range of possible measures - just like the requirements for data and processes - is wide and always depends on the individual case.
4. Clean up & adapt processes
In any case, the company must clean up its examined data stock, i.e. remove and correct erroneous data. This can be, for example, the automated checking of telephone numbers - an important measure and support for CRM projects, the help desk, complaint management or other customer contact management tasks. In this process, duplicates are automatically eliminated.
In addition to data cleansing, processes and system landscapes often have to be adapted. Once all areas have been adjusted accordingly, data quality is ideally at the maximum achievable level. Whether it remains constant, however, depends on further data and quality management throughout the company.
You might also be interested in:


